목표 시나리오
Python을 이용하여 스타벅스 홈페이지에 존재하는 메뉴들의 제품 정보(이미지, 영양정보 등)를 크롤링하기
1. 스타벅스 메뉴페이지의 모든 메뉴들의 상세 페이지를 탐색
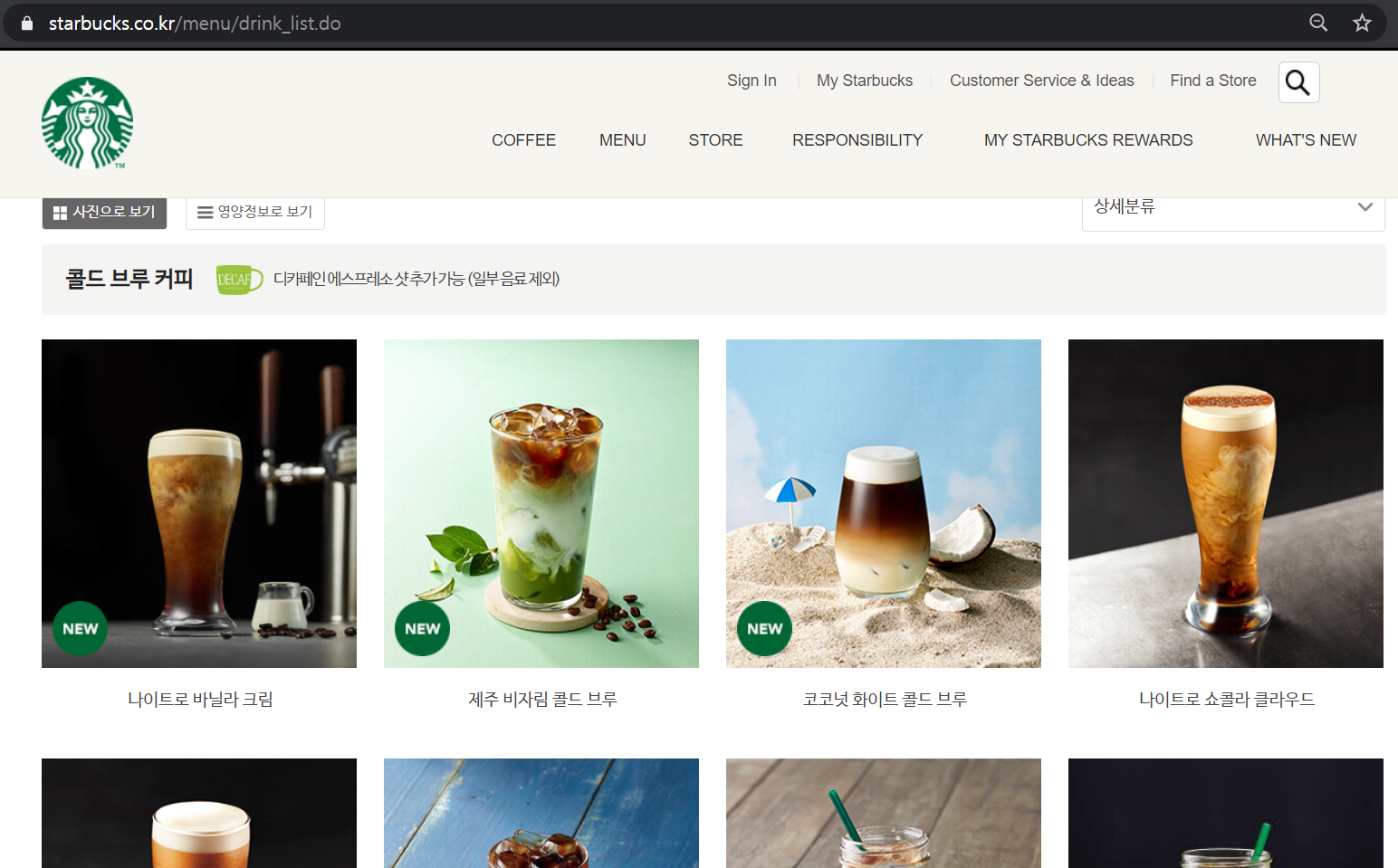
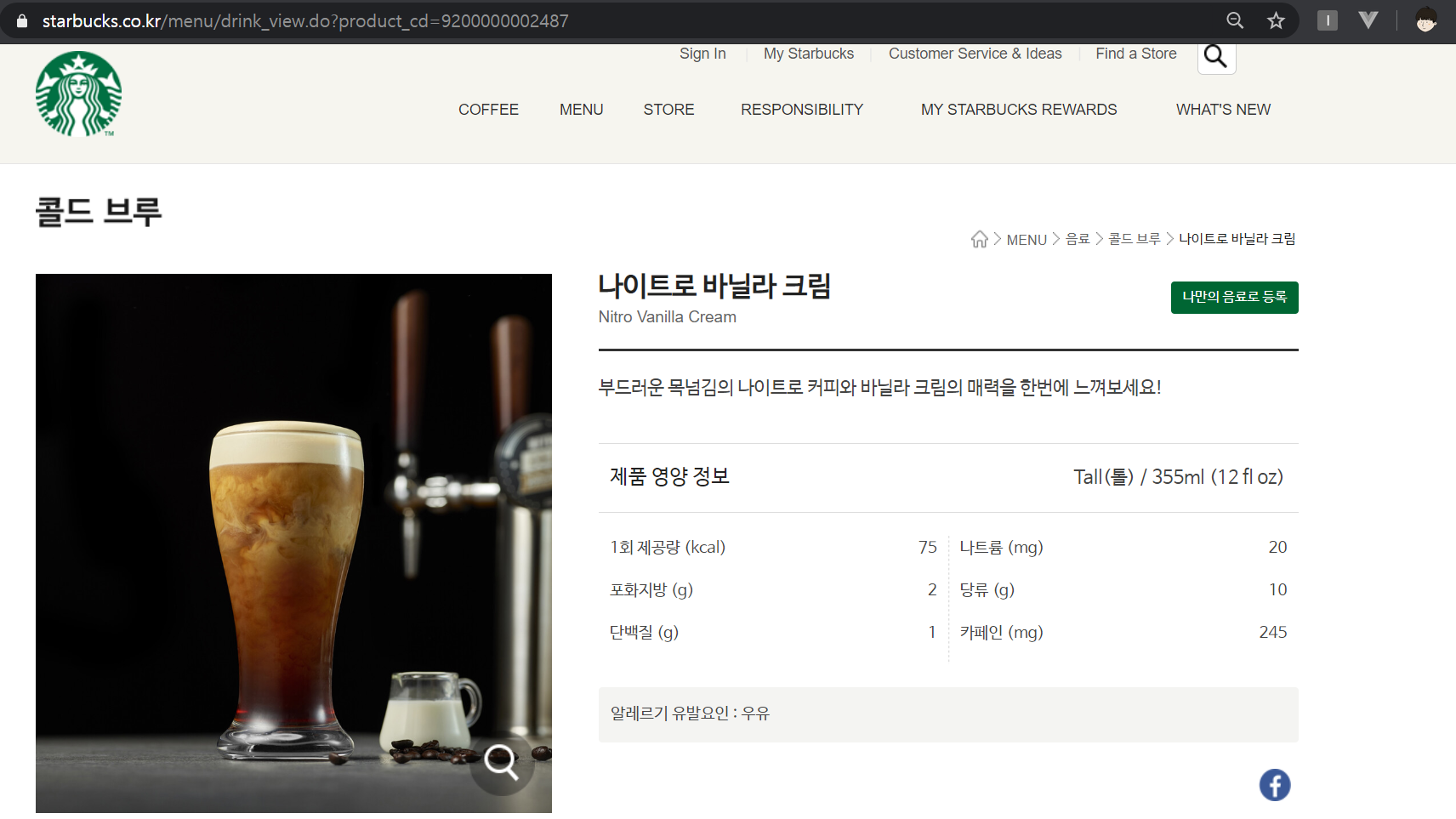
2. 각 페이지내의 이미지와 영양정보를 수집한다.
필요 라이브러리 설치
$ pip install beautifulsoup4
$ pip install selenium※ selenium을 구동하기 위해서는 WebDriver가 필요합니다. (WebDriver 설치하기)
웹 크롤링시 기본적인 웹 언어(HTML, CSS, JS)를 알면 원하는 정보를 효과적으로 추출할 수 있습니다.
스타벅스 메뉴들의 상세 페이지 주소는 https://www.starbucks.co.kr/menu/drink_view.do?product_cd=9200000002487로 되어있는데 product_cd=뒤의 제품 코드를 넣어주면 해당 페이지로 접근 가능합니다.
따라서 우리는 스타벅스 메뉴 페이지를 가서 현재 메뉴들의 product_cd들을 수집하겠습니다.
메뉴 페이지를 살펴보니 <div class="product_list"> </div> 안에 각 메뉴 항목들이 들어있습니다.

만약 BeautifulSoup만으로 해당 페이지에서 크롤링을 할 경우 '. product_list'를 찾을 수 없습니다.
Selenium없이 크롤링 Code
import requests
from bs4 import BeautifulSoup
response = requests.get('https://www.starbucks.co.kr/menu/drink_list.do')
html_source = response.text
soup = BeautifulSoup(html_source, 'html.parser')
result = soup.select('.proudct_list')
print(result)
# []이유는 해당 내용들은 초기 HTML에 있는게 아니라 JavaScript를 통해 동적으로 생성되는 내용이므로 BS4만으로는 해당 내용을 크롤링할 수 없습니다. 따라서 selenium을 통해서 JavaScript가 실행된 페이지를 가져오는 것이 필요합니다.
Selenium을 이용해 메뉴 페이지를 가져오고 각 메뉴의 prdouct_cd들은 .product_list > dd > a 를 찾은 다음 prod 속성을 가져오면 됩니다.

제품 코드 추출
from bs4 import BeautifulSoup
from selenium import webdriver
from pprint import pprint
# webdriver 실행
dr = webdriver.Chrome('C:/webdriver/chromedriver.exe')
# target page 접근
dr.get("https://www.starbucks.co.kr/menu/drink_list.do")
# html source 추출
html_source = dr.page_source
# BS로 html parsing
soup = BeautifulSoup(html_source, 'html.parser')
# 원하는 항목의 데이터만 추출
products = soup.select('.product_list dd a')
# 결과 확인
pprint(products)
# [<a class="goDrinkView" href="javascript:void(0)" prod="9200000002487"><img alt="나이트로 바닐라 크림" src="https://image.istarbucks.co.kr/upload/store/skuimg/2019/09/[9200000002487]_20190919181354811.jpg"/></a>,
# <a class="goDrinkView" href="javascript:void(0)" prod="9200000002672"><img alt="제주 비자림 콜드 브루" src="https://image.istarbucks.co.kr/upload/store/skuimg/2020/02/[9200000002672]_20200220135658603.jpg"/></a>,
# ...
# <a class="goServiceView" f_cate="//W0000001" href="javascript:void(0)" prod="9200000002757"><img alt="피치 젤리 아이스 티" src="https://image.istarbucks.co.kr/upload/store/skuimg/2020/04/[9200000002757]_20200403132717643.jpg"/></a>,
# <a class="goServiceView" f_cate="//W0000001" href="javascript:void(0)" prod="9200000002754"><img alt="피치 젤리 핫 티" src="https://image.istarbucks.co.kr/upload/store/skuimg/2020/04/[9200000002754]_20200403132406524.jpg"/></a>]]
이제 제품 List에서 제품 이름과 제품 코드를 얻기 위해 prod속성값과 img태그의 alt값을 추출하겠습니다.
# 제품 이름, 코드 추출
prod_cd = [[product['prod'], product.find('img')['alt']] for product in products]
# 결과 확인
pprint(prod_cd)
# [['9200000002487', '나이트로 바닐라 크림'],
# ['9200000002672', '제주 비자림 콜드 브루'],
# ['9200000002739', '코코넛 화이트 콜드 브루'],
# ['9200000001275', '나이트로 쇼콜라 클라우드'],
# ...
# ['9200000002757', '피치 젤리 아이스 티'],
# ['9200000002754', '피치 젤리 핫 티']]
이제 제품 코드로 각 상세 페이지에서 영양정보를 스크랩 합니다.
div.product_info_content 아래에 각 영양정보를 class를 찾고 그아래 dd의 값을 추출하면 됩니다.

신기하게도 사이트에 보이는 6가지 영양정보 외에도 트랜스지방, 콜레스테롤 등의 정보도 존재합니다.
import time
# result를 담을 빈 List 생성
result = []
# 제품별로 for loop
for prod in prod_cd:
container = dict()
cd = prod[0]
name = prod[1]
dr.get("https://www.starbucks.co.kr/menu/drink_view.do?product_cd={prod_cd}".format(prod_cd=cd))
html_source = dr.page_source
soup = BeautifulSoup(html_source, 'html.parser')
# 용량 정보
volume = soup.select_one('.product_info_head #product_info01').get_text()
# 제품 영양정보
kcal = soup.select_one('.product_info_content .kcal dd').get_text()
sat_FAT = soup.select_one('.product_info_content .sat_FAT dd').get_text()
protein = soup.select_one('.product_info_content .protein dd').get_text()
fat = soup.select_one('.product_info_content .fat dd').get_text()
trans_FAT = soup.select_one('.product_info_content .trans_FAT dd').get_text()
protein = soup.select_one('.product_info_content .protein dd').get_text()
sodium = soup.select_one('.product_info_content .sodium dd').get_text()
sugars = soup.select_one('.product_info_content .sugars dd').get_text()
caffeine = soup.select_one('.product_info_content .caffeine dd').get_text()
cholesterol = soup.select_one('.product_info_content .cholesterol dd').get_text()
chabo = soup.select_one('.product_info_content .chabo dd').get_text()
container['cd'] = cd
container['name'] = name
container['kcal'] = kcal
container['sat_FAT'] = sat_FAT
container['protein'] = protein
container['fat'] = fat
container['trans_FAT'] = trans_FAT
container['protein'] = protein
container['sodium'] = sodium
container['sugars'] = sugars
container['caffeine'] = caffeine
container['cholesterol'] = cholesterol
container['chabo'] = chabo
result.append(container)
# 트래픽 조절을 위해 3초간 pause
time.sleep(3)
pprint(result)
# [{'caffeine': '245',
# 'cd': '9200000002487',
# 'chabo': '10',
# 'cholesterol': '5',
# 'fat': '2.7',
# 'kcal': '75',
# 'name': '나이트로 바닐라 크림',
# 'protein': '1',
# 'sat_FAT': '2',
# 'sodium': '20',
# 'sugars': '10',
# 'trans_FAT': '0'},
# {'caffeine': '105',
# 'cd': '9200000002672',
# 'chabo': '49',
# 'cholesterol': '25',
# 'fat': '12',
# 'kcal': '340',
# 'name': '제주 비자림 콜드 브루',
# 'protein': '10',
# 'sat_FAT': '8',
# 'sodium': '115',
# 'sugars': '44',
# 'trans_FAT': '0.3'},
# ... ]
마지막으로 수집한 정보를 csv파일로 export합니다.
import pandas as pd
# DataFrame으로 변환
df = pd.DataFrame(result)
# csv파일로 저장
df.to_csv('./starbucks.csv', index=False)
# 데이터 확인
df실제 잘 저장되었는지 starbucks.csv파일을 열어봅시다.

< 다음 포스팅에서는 수집한 정보를 DB에 저장하겠습니다. >
전체 코드 정리
from bs4 import BeautifulSoup
from selenium import webdriver
from pprint import pprint
import time
import pandas as pd
# webdriver 실행
dr = webdriver.Chrome('C:/webdriver/chromedriver.exe')
# target page 접근
dr.get("https://www.starbucks.co.kr/menu/drink_list.do")
# html source 추출
html_source = dr.page_source
# BS로 html parsing
soup = BeautifulSoup(html_source, 'html.parser')
# 원하는 항목의 데이터만 추출
products = soup.select('.product_list dd a')
# 결과 확인
pprint(products)
# 제품 이름, 코드 추출
prod_cd = [[product['prod'], product.find('img')['alt']] for product in products]
# 결과 확인
pprint(prod_cd)
# result를 담을 빈 List 생성
result = []
# 제품별로 for loop
for prod in prod_cd:
container = dict()
cd = prod[0]
name = prod[1]
dr.get("https://www.starbucks.co.kr/menu/drink_view.do?product_cd={prod_cd}".format(prod_cd=cd))
html_source = dr.page_source
soup = BeautifulSoup(html_source, 'html.parser')
# 용량 정보
volume = soup.select_one('.product_info_head #product_info01').get_text()
# 제품 영양정보
kcal = soup.select_one('.product_info_content .kcal dd').get_text()
sat_FAT = soup.select_one('.product_info_content .sat_FAT dd').get_text()
protein = soup.select_one('.product_info_content .protein dd').get_text()
fat = soup.select_one('.product_info_content .fat dd').get_text()
trans_FAT = soup.select_one('.product_info_content .trans_FAT dd').get_text()
protein = soup.select_one('.product_info_content .protein dd').get_text()
sodium = soup.select_one('.product_info_content .sodium dd').get_text()
sugars = soup.select_one('.product_info_content .sugars dd').get_text()
caffeine = soup.select_one('.product_info_content .caffeine dd').get_text()
cholesterol = soup.select_one('.product_info_content .cholesterol dd').get_text()
chabo = soup.select_one('.product_info_content .chabo dd').get_text()
container['cd'] = cd
container['name'] = name
container['kcal'] = kcal
container['sat_FAT'] = sat_FAT
container['protein'] = protein
container['fat'] = fat
container['trans_FAT'] = trans_FAT
container['protein'] = protein
container['sodium'] = sodium
container['sugars'] = sugars
container['caffeine'] = caffeine
container['cholesterol'] = cholesterol
container['chabo'] = chabo
result.append(container)
# 트래픽 조절을 위해 3초간 pause
time.sleep(3)
pprint(result)
# DataFrame으로 변환
df = pd.DataFrame(result)
# 데이터 확인
df
'취미개발' 카테고리의 다른 글
| Windows OpenSSH Server 설치 및 설정 (0) | 2023.03.17 |
|---|---|
| Python Selenium 시작하기 (webdriver 설치하기) (0) | 2020.04.20 |
| AirFlow 환경 만들기(2) - Airflow 설치하기(feat. docker) (0) | 2020.02.21 |
| AirFlow 환경 만들기(1) - Postgres 설치하기(feat. docker) (0) | 2020.02.21 |


